DS - Pandas - DataFrame
This is part of a series of articles dedicated to study Data Science using Python. This article tries to explain the basics of using the DataFrame abstraction from the Pandas library.
What is a DataFrame ?
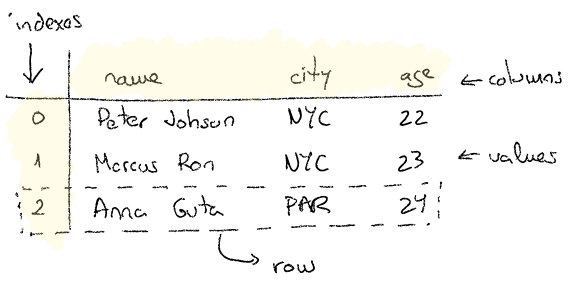
You can think of a DataFrame as a 2 dimensional Series object. If you take any row of the next example, you would be getting Series object. The same thing happens if you take a given column values.
Creating a DataFrame
You can create a DataFrame out of Series objects where each series represents a row of data:
import pandas as pd
peterj = pd.Series({"name": "Peter Johnson", "city": "NYC", "age": 22})
marcus = pd.Series({"name": "Marcus Ron", "city": "NYC", "age": 23})
annagu = pd.Series({"name": "Anna Guta", "city": "PAR", "age": 24})
people = pd.DataFrame([peterj, marcus, annagu])
peopleOr just from a list of dictionaries:
import pandas as pd
peterj = {"name": "Peter Johnson", "city": "NYC", "age": 22}
marcus = {"name": "Marcus Ron", "city": "NYC", "age": 23}
annagu = {"name": "Anna Guta", "city": "PAR", "age": 24}
people = pd.DataFrame([peterj, marcus, annagu])
peopleEither way you would get the following data structure:

We might want to change the default integer index by providing our own. For instance we are providing the symbol of a given spanish university:
import pandas as pd
peterj = {"name": "Peter Johnson", "city": "NYC", "age": 22}
marcus = {"name": "Marcus Ron", "city": "NYC", "age": 23}
annagu = {"name": "Anna Guta", "city": "PAR", "age": 24}
people = pd.DataFrame([peterj, marcus, annagu], index=["UAM", "UAM", "UCM"])
peopleThat would get us:

Accessing data: iloc, loc
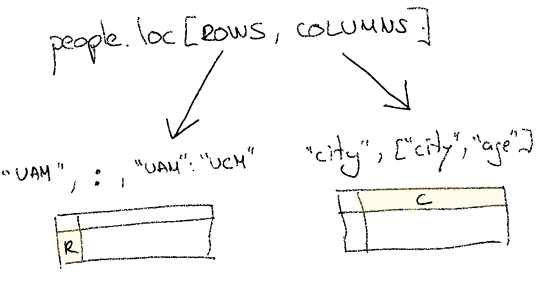
The same way we used these functions to access data in a Series object, we can use it in a DataFrame object. For example, if we’d like to access every person attending a certain university we can use the loc function:
loc
import pandas as pd
peterj = {"name": "Peter Johnson", "city": "NYC", "age": 22}
marcus = {"name": "Marcus Ron", "city": "NYC", "age": 23}
annagu = {"name": "Anna Guta", "city": "PAR", "age": 24}
people = pd.DataFrame([peterj, marcus, annagu], index=["UAM", "UAM", "UCM"])
people.loc["UAM"]
Although in this particular case a new DataFrame is return, however depending on how many rows this call is returning, the type will be a Series object if it’s just one row, or a DataFrame if multiple rows are return.
You can go one step further and not only filter by index but also select a given set of columns:
loc full syntax
people.loc["UAM", ["name", "age"]]Basically you have to remember that loc and iloc can be called with two parameters, the first one representing the rows we’d like to select, and the second one representing which columns we would like to show.
The iloc works the same but, instead of using an index value, you should use an integer representing the position of both rows and columns. Following the previous example, to get the same result with iloc:
iloc full syntax
people.iloc[0, [0, 2]]What if you only want to get all values of a certain column. The brackets syntax can be used to select only a given column. For instance, getting all cities in the DataFrame:
column selection bracket syntax
people["city"]As a rule of thumb, stick to bracket syntax to get ONLY column values, and iloc and loc to do a more advanced row selection.

Dropping columns/rows
When cleaning messy data, we might want to get rid of unnecessary data. That could mean get rid of some rows or maybe some columns. To get a new DataFrame without rows indexed by index value "UAM":
drop rows by index value
import pandas as pd
peterj = {"name": "Peter Johnson", "city": "NYC", "age": 22}
marcus = {"name": "Marcus Ron", "city": "NYC", "age": 23}
annagu = {"name": "Anna Guta", "city": "PAR", "age": 24}
people = pd.DataFrame([peterj, marcus, annagu], index=["UAM", "UAM", "UCM"])
new_people = people.drop("UCM")This returns a new DataFrame instead of changing the source DataFrame in place. For changing the DataFrame in place set the inplace parameter to True:
drop rows in place
people.drop("UCM", inplace=True)However if you’d like to drop certain columns you can change the axis you are looking into, where axis=0 is for deleting rows and axis=1 for deleting columns:
drop columns
import pandas as pd
peterj = {"name": "Peter Johnson", "city": "NYC", "age": 22}
marcus = {"name": "Marcus Ron", "city": "NYC", "age": 23}
annagu = {"name": "Anna Guta", "city": "PAR", "age": 24}
people = pd.DataFrame([peterj, marcus, annagu], index=["UAM", "UAM", "UCM"])
new_people = people.drop("age", axis=1)
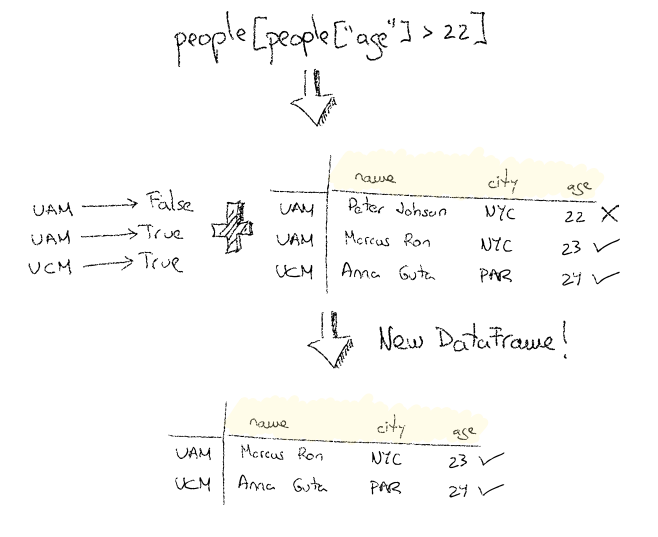
Filtering a DataFrame: boolean masks
The same way we query a database using SQL expressions it would be nice to have a where-like expressions to query a given DataFrame. There is such type of expression, the Boolean Mask.
A boolean Mask is an expression representing a filter that can be applied to a given DataFrame. By itself represents a Series object, but when applied to a DataFrame it returns a new filtered DataFrame.
In the following example I’d like to get a DataFrame containing people older than 22 years old. First of all I need to create a boolean mask about the age column.
creating a boolean mask
import pandas as pd
peterj = {"name": "Peter Johnson", "city": "NYC", "age": 22}
marcus = {"name": "Marcus Ron", "city": "NYC", "age": 23}
annagu = {"name": "Anna Guta", "city": "PAR", "age": 24}
people = pd.DataFrame([peterj, marcus, annagu], index=["UAM", "UAM", "UCM"])
older_than_22 = people["age"] > 22
older_than_22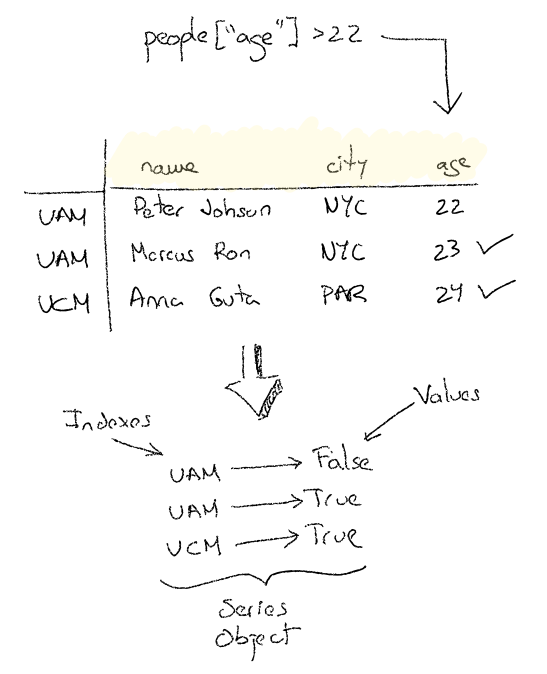
As you can see the boolean mask itself represents a list of indexes. Therefore I can apply those indexes to filter out our people DataFrame to get only the interesting rows in a new DataFrame instance.
applying a boolean mask to a DataFrame
people_older_than_22 = people[older_than_22]
people_older_than_22