DS - Pandas - Merging DataFrames
This is part of a series of articles dedicated to study Data Science using Python. This article shows a couple of basic examples on DataFrame merging.
One is easy, two or more are…normal?
That’s true, more than often you have to deal with more than one data source in order to get some insight about the problem you want to tackle. Maybe you can transform your source files in order to get just one file, but most of the time you can’t or is very time consuming.
Instead of doing that, you can create Pandas DataFrames and then merge those DataFrames with some logic in order to get the result that you wanted. Most of the time you will want to either concatenate data or join data.
Appending
So basically we want more than one DataFrame and we’d like to concatenate them in just one.
Rows
The easiest use case is when we’ve got two files with the same format (same columns, and type of data) and we want to concatenate both files one after the other. Here we have two DataFrames, both with the same type of data.
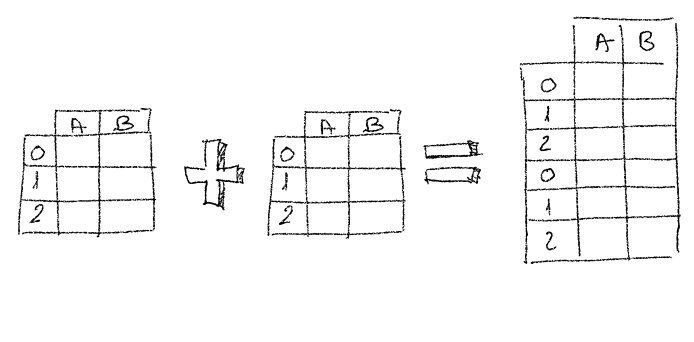
concatenate rows from two DataFrames
df1 = pd.DataFrame([{"name": "john", "age": 22}, {"name": "peter", "age": 34}])
df2 = pd.DataFrame([{"name": "anna", "age": 34}, {"name": "uri", "age": 43}])
result = pd.concat([df1, df2])
result
all_data = pd.concatenate(data_2018, data_2019)
all_dataname |
age |
|
0 |
john |
22 |
1 |
peter |
34 |
0 |
anna |
34 |
1 |
uri |
43 |
Now all_data has all the rows from both DataFrames but notice how indexes are repeated. We may want to reset the index for the new DataFrame.
import pandas as pd
df1 = pd.DataFrame([{"name": "john", "age": 22}, {"name": "peter", "age": 34}])
df2 = pd.DataFrame([{"name": "anna", "age": 34}, {"name": "uri", "age": 43}])
result = pd.concat([df1, df2]).reset_index(drop=True)
resultname |
age |
|
0 |
john |
22 |
1 |
peter |
34 |
2 |
anna |
34 |
3 |
uri |
43 |
Columns
For example, think of a series of files, each file represents a part of the whole data and you’d like to have everything in just one DataFrame. So basic assumption is, there’re the same amount of lines in every DataFrame.
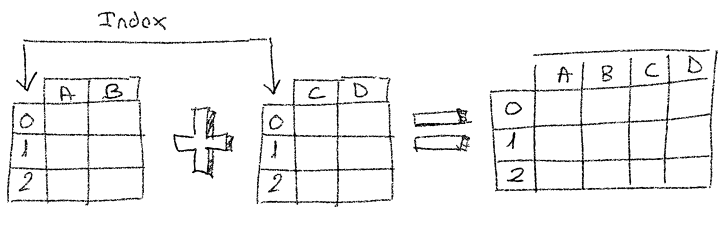
In this occasion we have:
-
One DataFrame has the names of the students and the other has the ages of the students.
-
Both DataFrames have the same number of rows
-
Both DataFrames are sorted in a way that rows in one DataFrame match the rows in the other DataFrame so names are ending up matching the right ages.
appending columns
df1 = pd.DataFrame([{"name": "john"}, {"name": "peter"}, {"name": "anna"}, {"name": "uri"}])
df2 = pd.DataFrame([{"age": 22}, {"age": 34}, {"age": 34}, {"age": 43}])
result = pd.\
concat([df1, df2], axis=1).\
reset_index(drop=True)
resultThis time is not necessary to reset the index as the second DataFrame is using the first DataFrame index.
Joining
By joining I mean to merge different datasets together following certain rules. Imaging having students' names and their ids in one dataset and their ids and ages in another and you’d like to merge them all in just one dataset, matching records in both datasets by their ids.
Sometimes there will be ages with ids that don’t match any record in the other dataset, then, What do we do ?
-
Should we discard them ?
-
Should we add them in the merged dataset with missing data ?
Depending on the situation you may want to do the former or the latter.
Inner
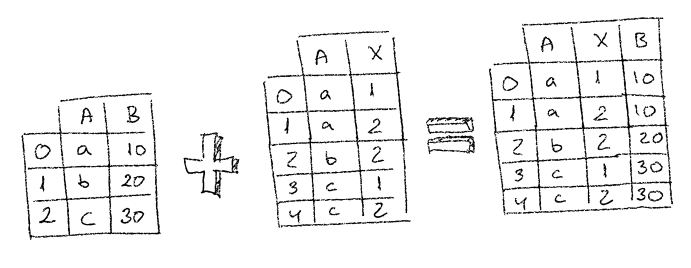
When doing inner joins what we try to achieve is to match rows from both DataFrames by something they have in common. It could be the row index, or a row column value.
When doing inner join by DataFrame index it seems pretty similar to the appending columns example. Here we are joining datasets by their index, so it loops over all the rows in one dataframe and if the other dataframe has a row with the same index then all columns will be added to the next row in the new DataFrame.
| Remember that in Pandas DataFrame, by default a DataFrame has a numerical index that begins with integer 0 and follows an incremental sequence. |
So bottom line is it will merge all rows with the same index.
df1 = pd.DataFrame([{"name": "john"}, {"name": "peter"}, {"name": "anna"}, {"name": "uri"}])
df2 = pd.DataFrame([{"age": 22}, {"age": 34}, {"age": 34}, {"age": 43}])
merged = pd.merge(df1, df2, left_index=True, right_index=True)
mergedSee how I’m telling the merge function to use indexes in both DataFrames to do the join. You can change this in order to chose which DataFrame’s index has to be used to do the join.
But there’re plenty of times when different datasets don’t have their records in the same order or the index they’re store doesn’t correspond to their identity. Moreover their ids are values in one of the columns of the DataFrame. Basically like in a database table with a primary key.
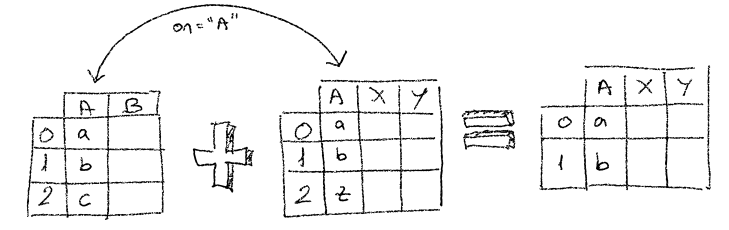
inner join by column
df1 = pd.DataFrame([
{"id": 1, "name": "john"},
{"id": 2, "name": "peter"},
{"id": 3, "name": "anna"}])
df2 = pd.DataFrame([
{"id": 1, "age": 22},
{"id": 2, "age": 34},
{"id": 3, "age": 34},
{"id": 4, "age": 43}])
merged = pd.merge(df1, df2, how="inner", on="id")
mergedid |
name |
age |
|
0 |
1 |
john |
22 |
1 |
2 |
peter |
34 |
2 |
3 |
anna |
34 |
-
The merge method is invoked with how="inner" to tell the function not to add a row if both DataFrames don’t have a row with the same matching key (on="id").
We can see that because there’s no "id": 4 in the left DataFrame, we cannot match any record in the second DataFrame, therefore the result doesn’t have 4 rows but only 3. This works pretty much as a relational database inner join.
Outer
With the inner join approach we were discarding some rows if the column’s value didn’t match. But what if we wanted to add rows not matching the key ? What would happen ? Lets review the previous example, but instead of using inner join, we’re using outer as the joining strategy.
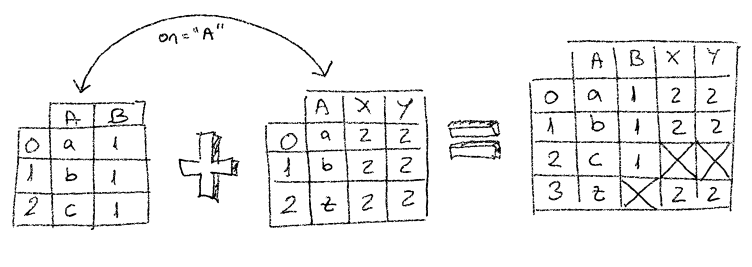
outer join
df1 = pd.DataFrame([
{"id": 1, "name": "john"},
{"id": 2, "name": "peter"},
{"id": 3, "name": "anna"}])
df2 = pd.DataFrame([
{"id": 1, "age": 22},
{"id": 2, "age": 34},
{"id": 3, "age": 34},
{"id": 4, "age": 43}])
merged = pd.merge(df1, df2, how="outer", on="id")
mergedid |
name |
age |
|
0 |
1 |
john |
22 |
1 |
2 |
peter |
34 |
2 |
3 |
anna |
34 |
3 |
4 |
Nan |
43 |
Completing data
There’s another scenario where you can have two DataFrames and one of them is like a master table that could be use to complete information in the other DataFrame.
Imaging there’s a reference of Formula 1 circuits, and another DataFrame having the drivers that have participated in a specific race, and we want to know how many kilometers did the drivers.
getting all relevant information altogether
circuits = pd.DataFrame({"circuit": ["Monza", "Spa"], "length": [5, 4]})
drivers = pd.DataFrame([
{"name": "Lewis Hamilton", "circuit": "Spa", "laps": 53},
{"name": "Carlos Sainz", "circuit": "Spa", "laps": 43}])
circuits_drivers = pd.merge(circuits, drivers, how="right", on="circuit")
circuits_driverscircuit |
length |
name |
laps |
|
0 |
Spa |
5 |
Lewis Hamilton |
53 |
1 |
Spa |
5 |
Carlos Sainz |
53 |
getting km per pilot
circuits_drivers["km"] = circuits_drivers["laps"] * circuits_drivers["length"]
spa_stats = circuits_drivers.\
drop(["circuit", "length"], axis=1, inplace=False)
spa_statsname |
laps |
km |
|
0 |
Lewis Hamilton |
53 |
212 |
1 |
Carlos Sainz |
43 |
172 |
These are very basic examples of concatenating, and merging DataFrames, there’s a section only for that matter in the Pandas site, check links in the Resources section: