DS - Machine Learning key concepts
As my next step in Data Science world, this week I’m starting a Machine Learning Course. Although it seems like an intimidating path ahead, lets take it step by step and lets review some basic concepts on Machine Learning.
What is Machine Learning ?
Machine learning (ML) is an area of artificial Intelligence (AI) focused on building software capable of improving over time through experience. Searching a little bit about the topic will show you that ML is not new in town. Although it’s an area of research already present in the 50’s, however it remained mainly in the academia, the military and some large corporations. It’s only nowadays when it’s has become a trending technology where everybody wants to jump in. Some of the reasons behind this change are:
-
ML benefits from vast amounts of data. In the early days data was scarced and hard to collect, now is easier to access or to create large datasets.
-
ML benefits from series of modern coded algorithms. Today there’re plenty of new algorithms already coded and freely available.
-
ML benefits from powerful computers. A smart phone today has more power than a super computer in the 70’s.
Is an area of AI focused on building software capable of improving over time through experience
Why you should (not) learn ML ?
While preparing this entry, I came across some very interesting videos (see resources) talking about how people are learning ML maybe because the wrong reasons. The truth is that ML has an enormous hype and that could force some people into think that there’s a need to learn it, even if they don’t know why. Some of these (wrong?) ideas on ML:
-
ML is the next big thing: Well, it’s a new exciting area of knowledge of course, but there’re many others, like distributed computing for example. People who gets excited for every new thing tend to lose interest as soon as there’s something newer.
-
ML is going to improve my career path: Well, having a course on ML is not gonna get you more dollars in your bank account by itself, the experience on working with ML will. You have to make sure you’ll like the change, maybe there’re many other ways of improving your current situation without involving ML.
And even once you’ve decided the why, there’s still the problem of having a plan. Having a plan involves how, and what. How are you going to do it ? Are you going to do online courses ? Do an intership in an ML project ? And, in case you’re doing an online course, What type of course will fullfil your goals ?
Not having a plan could lead you to a paralisis analysis situation and the Buridan’s ass problem (aka donkey problem). There are many people getting stuck in the following question: Am I learning ML to build a product or just for research ? Well lesson learned is that to avoid paralisis analysis you must choose one or the other quickly, don’t waste your time.
Having said that, I thought it would be great to answer these questions to myself:
Why are you learning ML ?
I’m learning ML because most of the software projects I was working on lately required ML for a good reason (computer vision applied to security, healthcare diagnosis), and I felt I was missing a very important part of the project. I think ML is really key in many software development projects and I also think that my work as software engineer can be improved by having some practical knowledge on ML. Even if I don’t code myself the ML solution, I will be better on understanding how to integrate those solutions in the projects I’m involved with.
How are you going to do it ?
To me, taking online courses is the most convenient way of learning ML. Moreover now is almost mandatory because of the pandemic. Another part of the plan is to write as much as I can about what I’m learning. That, I think, will reinforce my learning process.
What exactly are you going to begin with ?
General online course giving me a general overview of the most used techniques. The course has to be practical, real coding examples.
How ML works ?
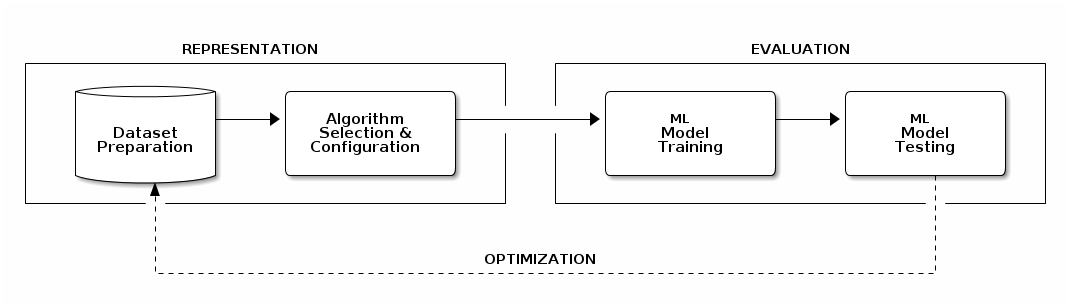
Although there’re different methods to build ML software, they all share a common iterative process with three phases:
-
In the first part, called representation, we should find a representative dataset and a suitable algorithm for the problem at hand.
-
Then we use both, dataset and algorithm, to train a software model to make predictions. Afterwards the model performance is evaluated with new datasets. Training and evaluation are part of the evaluation phase.
-
Finally if we’re not satisfied with the results we can always iterate over the process to optimize the results. This final part as you may guess is called optimization.
Figure 1. ML processes are iterative
Representation
For instance, if we’d like to create a software capable of giving fair loans avoiding risky clients we’ll need as many historical records as we can get. The more the data, the better. But there’re also some other considerations to take into account. Maybe the data contains some sensitive information we should skip before feeding the system, whether because of privacy reasons or because it could lead to unwanted biased results. Remember that the lack of some information could also end having unfair or biased results. Bottom line during dataset preparation you need to make sure the data is unbiased and relevant.
The type of algorithm to use depends on the type of the data, the amount of data, and the type of the problem to be solved. In practice most of the algorithm selection usually depends on the type of strategy selected: supervised, unsupervised, semi-supervised, or reinforced. There’re algorithms that fit best in one strategy than others.
The training dataset and the algorithm to train the model
Evaluation
Once we’ve decided which algorithm to use we need to evaluate how it works . We need to create a model and train it with a training dataset. Later on the trained model will be used to make predictions on new data. Finally once the training has finished we can now use the model with the testing dataset to see if the predictions over the trained dataset are correct.
Model creation and testing the model with the testing dataset
Optimization
If we’re happy with the model predictions we’ve finished for now, if not, we should iterate to see how we can improve the results:
-
Maybe we realize the data was not accurate, maybe it was biased somehow
-
Maybe we can use a more suitable algorithm
-
Maybe the algorithm is correct but we can customize its parameters a little bit
Did I get the expected performance ?
Machine Learning methods
According to Wikipedia there’re a few ML methods, but now that I’ve just started looking into ML I’m focusing on supervised, and unsupervised methods.
Supervised
In the supervised method, there’s a labeled dataset, meaning that for every set of features there’s what is called a target value, this target value could be discrete (e.g. a label) or continuous (e.g a date). Depending on the type of the target values problems will fit into classification (discrete) or regression (continuous) problems.
Supervised method requires labeled data
Classification
Here the goal is to predict the target value (categorical class labels) of new instances based on training data. For example, check the following dataset:
| WHEELS | MODEL | BRAND | COLOR | TYPE_NAME | TYPE |
|---|---|---|---|---|---|
2 |
CBR 600 |
HONDA |
RED |
BIKE |
1 |
4 |
F450 |
FERRARI |
RED |
CAR |
0 |
2 |
SV650 |
SUZUKI |
BLUE |
BIKE |
1 |
4 |
SPACE |
RENAULT |
YELLOW |
CAR |
0 |
By looking at the features, WHEELS could be useful when trying to predict if something is a car or a bike. Once we’ve chosen the most representative features, we build the model. Then the model is evaluated with a testing dataset to see how well the algorithm predicts target values. When the target value is discrete like in this example, you are facing a classification problem. For example, if I use the following as an input to the model built with the previous table:
| WHEELS | MODEL | BRAND | COLOR |
|---|---|---|---|
2 |
FZR 600 |
YAMAHA |
WHITE |
I would expect the algorithm to return the target value 1 which is the value of the type BIKE.
Classification is about discrete values
Regression
A regression problem is when the target value is continuous such as "height" or "temperature". For instance, this is a sample of a training dataset of housing prices in a given neigbourghood:
| ROOMS | PRICE |
|---|---|
2 |
200000 |
2 |
205000 |
3 |
250000 |
4 |
300000 |
Now that we have a training dataset, we need to look for a regression algorithm to build the model. Testing the model should return a prediction on housing prices using the number of rooms as the input. Graphically, the result for any new input would be a point along the regression line (orange):
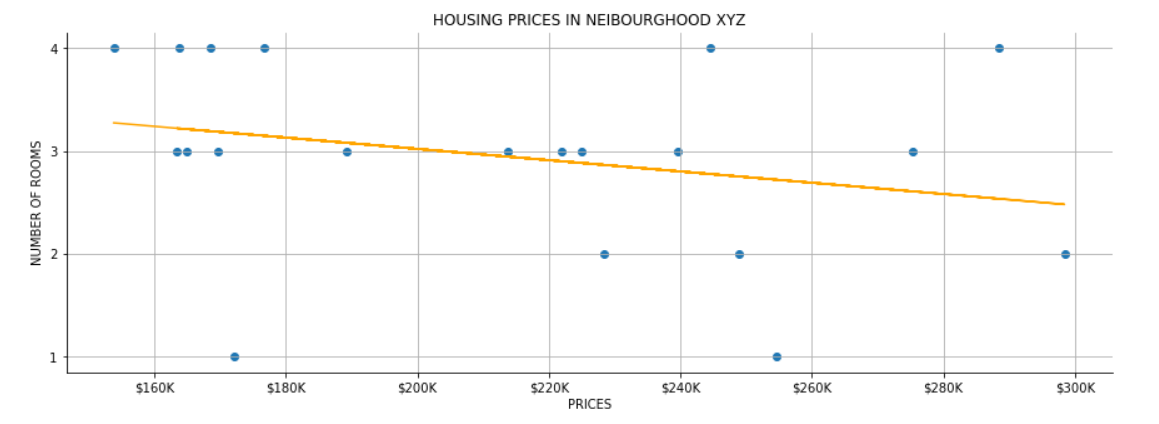
Figure 2. Regression
Regression is about continuous values
Unsupervised
Unsupervised methods try to get some insight or knowledge in data when labels are not available. There’s also a main distinction between those problems where the unsupervised method will try to find groups in the data (clustering) and those where the algorithm will try to look for unusual patterns (also called outliers).
|
|
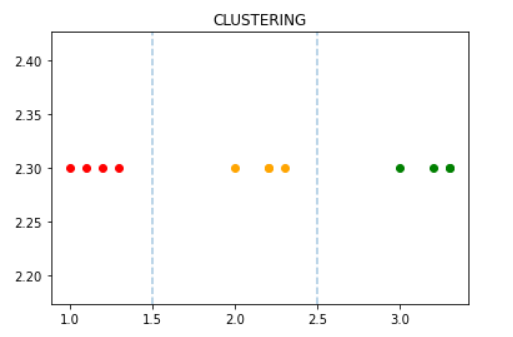
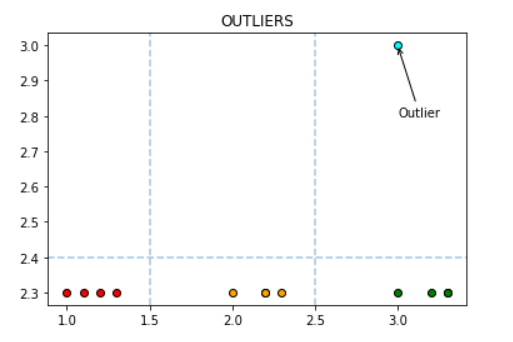
In a non labeled dataset unsupervised algorithms look for groups and patterns
There’s also a semi-supervised method. It’s normally very useful when not having enough labelled data. This approach combines a small amount of labeled data with a large amount of unlabeled data during training.
Other Resources
-
ML courses: A github repository with ML resources (books and courses links)
-
Detectron2: FAIR’s next-generation platform for object detection and segmentation