import pandas as pd
firewall = pd.read_csv('firewall.csv')
# simplifying dataframe column names
firewall.columns = [
'source',
'destination',
'nat_source',
'nat_destination',
'action',
'b_total',
'b_sent',
'b_received',
'packets',
'time',
'p_sent',
'p_received'
]
firewall.head()Logistic Regression: firewall rules
Although Logistic regression is a regression technique, due to the logistic function applied to it, it can constraint target values from a linear regression into discrete values and therefore act as a classification technique. Why not using KNN classification ? Well as a regression technique it benefits from regularization, so for a huge number of features it could reduce dimensionality.
There are three types of logistic regression:
-
binary: only two possible target values
-
multinomial: several possible target values without ordering
-
ordinal: several possible target values with a specific ordering
Classifying firewall rules
I’m practicing Binary Logistic Regression with UCI’s Internet Firewall Data which is a data set collected from the internet traffic records on a university’s firewall. UCI datasets are sorted depending on whether they’re good candidates for regression, classification or for both. In this ocassion I’d like to classify a set of firewall rules into two target values allowed or not allowed. Lets load the data and see how it looks:
loading and simplifying data
Because I’d like to do a binary classification, I need to narrow down the multi-valued column action:
action has several possible values
firewall['action'].unique()array(['allow', 'drop', 'deny', 'reset-both'], dtype=object)That’s why I’m creating the allowed column with only two possible values 1 for allow and 0 for the rest:
create label column
# simplifying actions to allowed or not allowed
firewall['allowed'] = firewall['action'].apply(lambda tag: 1 if tag == 'allow' else 0)
firewall = firewall.drop('action', axis=1)
firewall.head()
As usual, first I’d like to see the correlation matrix to see which features are the best to use in the logistic regression training:
correlation matrix
import seaborn as sns
import numpy as np
import matplotlib.pyplot as plt
corr_matrix = np.corrcoef(firewall.T)
plt.figure(figsize=(10, 10))
sns.heatmap(
corr_matrix,
cbar=False,
annot=True,
square=True,
xticklabels=firewall.columns,
yticklabels=firewall.columns)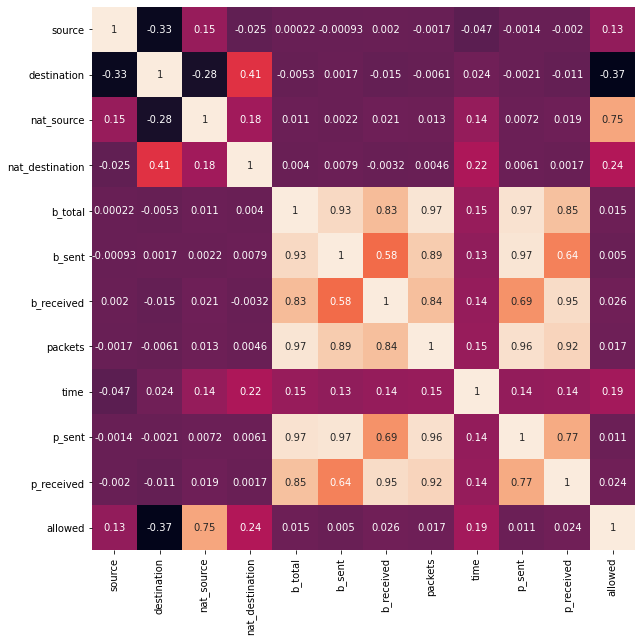
It seems that nat_source, nat_destination and time have the highest rates. With that in mind, I can now create X and y variables and the training and test sets:
features and training/test sets
from sklearn.model_selection import train_test_split
label = 'allowed'
features = ['nat_source', 'nat_destination', 'time']
X = firewall[features]
y = firewall[label]
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=50)Because there are several features working in different scales (e.g. time, ports) it would be better to apply some normalization to the feature set, in other words, I need to transform them to a common scale. For that I’m using the MinMaxScaler transformation.
scaling features
from sklearn.preprocessing import MinMaxScaler
# needed to reduce complexity
# https://stackoverflow.com/questions/62658215/convergencewarning-lbfgs-failed-to-converge-status-1-stop-total-no-of-iter
scaler = MinMaxScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)Now I can fit the LogisticRegression class with the training scaled dataset, check the score for training and test set, and see how well the model performs.
applying regression
from sklearn.linear_model import LogisticRegression
logistic = LogisticRegression().fit(X_train_scaled, y_train)
logistic.score(X_train_scaled, y_train), logistic.score(X_test_scaled, y_test)Which returns the following scores:
scores
(0.9711489552178071, 0.9730818531404505)Finally I’m picking the first two samples with different allowed value to see if the prediction works:
checking sample
validation_test_set = (firewall
.drop_duplicates(subset='allowed', keep="first")
.copy()
.reset_index(drop=True))
validation_test_x = validation_test_set.loc[:, features]
validation_test_y = validation_test_set.loc[:, label]
validation_test_x_scaled = scaler.transform(validation_test_x)
logistic.predict(validation_test_x_scaled) == [1, 0]Unfortunately this is not a good proof, these two samples were already part of the training or test datasets. As a reminder for my future self I should be keeping some part of the source dataset away from the training/test datasets to do a more serious validation at the end of the process.