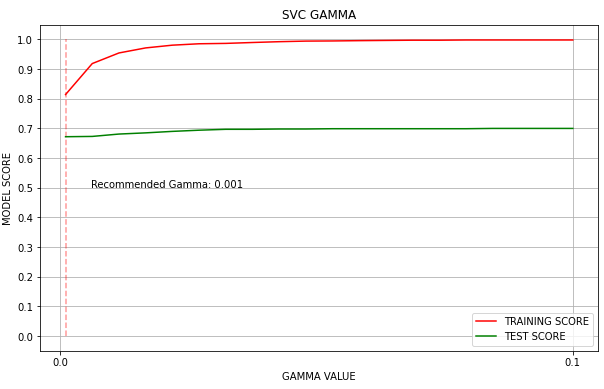
SVM clearly explained!
Here I’m just working with a particular case of SVM, if you’d like to known more, I really recommend you this wonderful video explaining how SVM works in a nutshell for linear and non linear spaces. There’re also a few other references in the resources section.